Chargement de fichiers avec TOS et PDI
Pour faire suite à nos deux premiers articles sur la mise en place de Talend Open Studio et de Pentaho Data Integration, nous allons effectuer une petite tansformation/job sur les 2 outils afin de comparer réellement leur usage.
Pour cela, nous utilisons un fichier CSV de régularité mensuelle des TGV.
Nous ferons relativement simple en chargeant le fichier puis en sauvegardant les données dans une base postgres.
Préparation de la base de donnée
Si vous souhaitez avoir une base de donnée prête en quelques minutes, prenez l'image docker de postgres puis faite un run:
docker run --name demoDb \
--restart=unless-stopped \
-v POSTGRES_DB_DATA:/var/lib/postgresql/data \
-e POSTGRES_PASSWORD=password \
-p 5432:5432 \
-d postgres:9.6.2
Ensuite, vous pouvez utiliser pgAdmin pour configurer la base de donnée. Après avoir créé une base de démo, nous allons pouvoir démarrer les chargements.
Chargement avec TOS
Nous utilisons ici la version 6.4.
Après avoir lancé l'application, on commence par créer un nouveau Job.
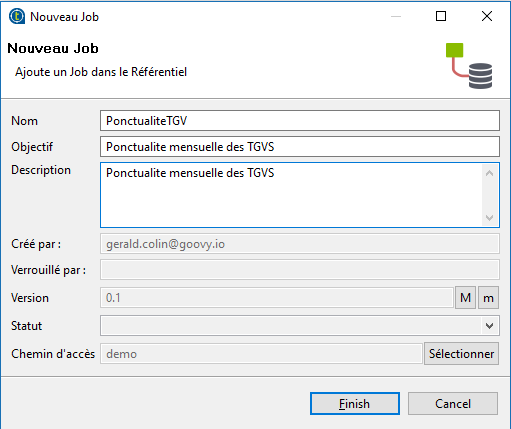
Ensuite, nous allons paramétrer l'accès à la base de donnée. Dans TOS, cela se fait dans les métadonnées ainsi nous pourrons réutiliser les identifiants de connexion dans d'autres jobs.
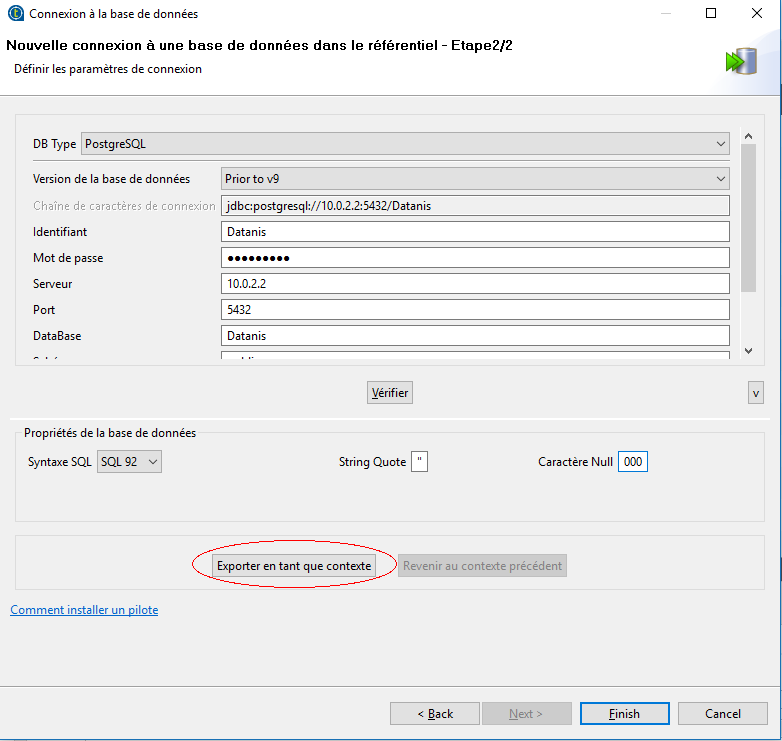
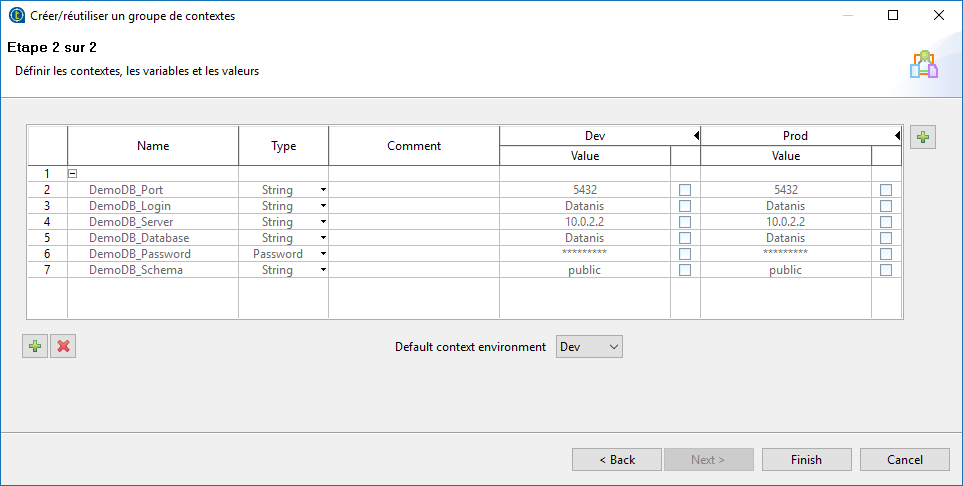
Après avoir testé la bonne connexion à la base, nous allons exporter en tant que contexte les informations. Cela nous permet de créer 2 environnements, un pour le développement et un pour la prod.
Pour le paramétrage du fichier, nous allons aussi utiliser les métadonnées mais cette fois pour un fichier délimité.
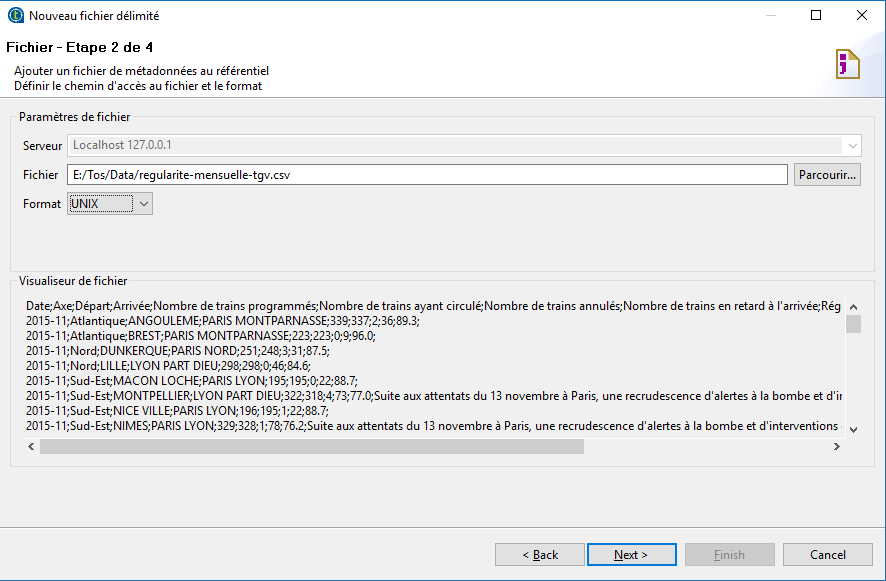
et dans l'écran suivant, nous paramétrons les caractéristiques du fichier.
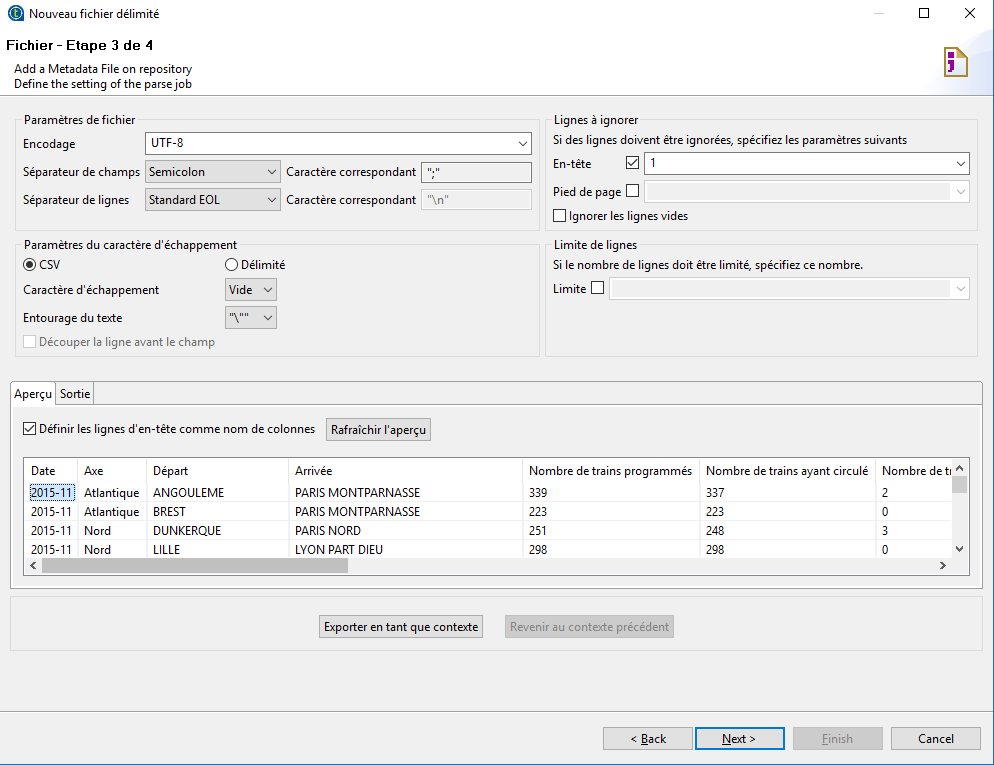
et nous utilisons ces données dans le Job créé avec un tFileInputDelimited et un tPostgresOutput.
Le paramétrage de chacun des composant se fait simplement en réutilisant les propriétés de réferentiel.
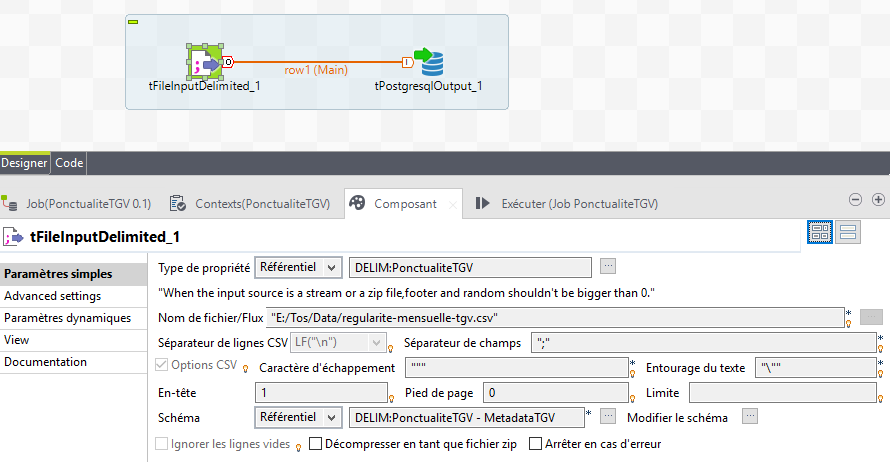
et pour la base de donnée
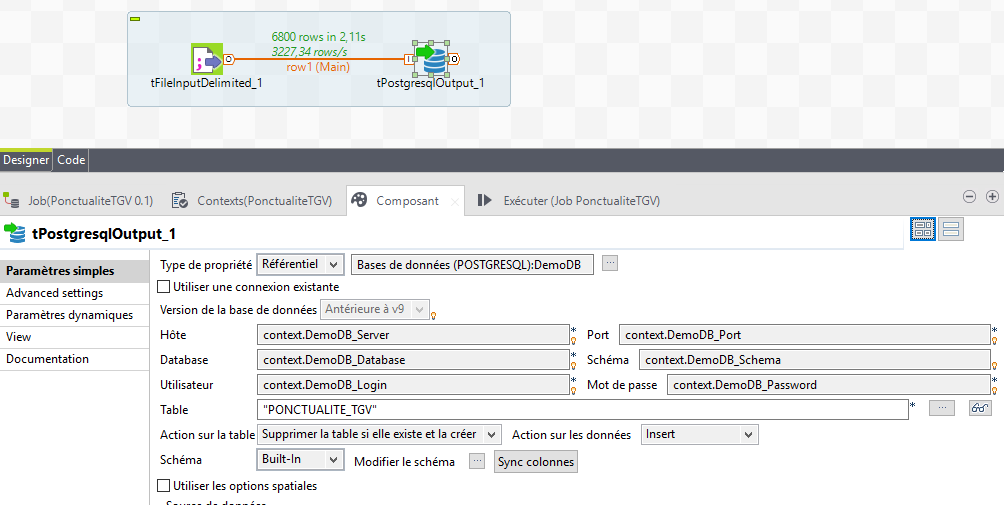
A noter que pour la base de donnée, il faudra changer le champ commentaire en TEXT et aussi la détection de la largeur des colonnes ne se fait pas en prenant le fichier jusqu'au bout.
On peut vérifier que les données sont bien en base
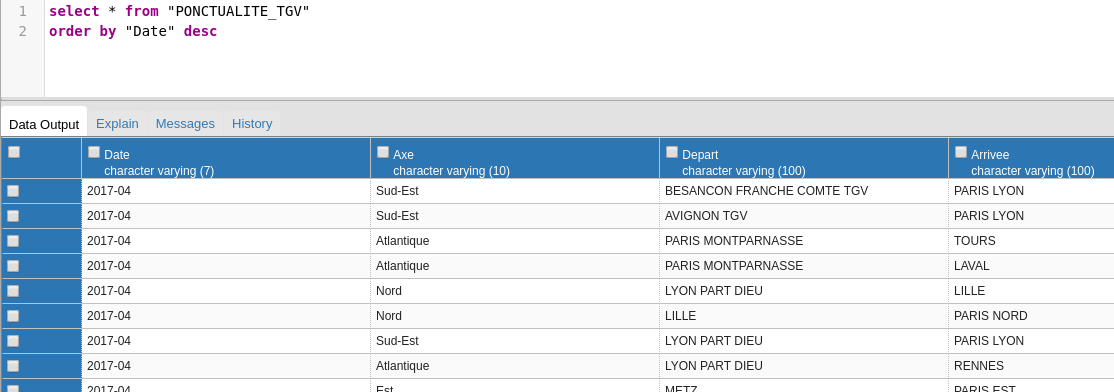
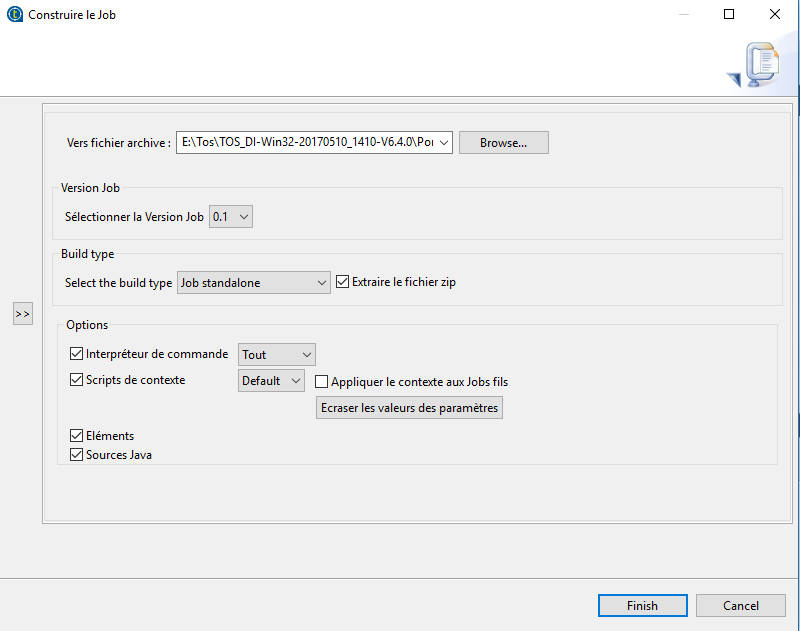
Une fois le job done, vous pouvez exporter facilement en un script qui sera ensuite executé en standalone ou intégré dans un serveur. Cela facilite la création de jobs schédulés.
Chargement avec PDI
Nous utilisons ici la version 7.1.
Créez une nouvelle transformation (click droit sur le folder transformation).
Puis nous ajoutons un "CSV File Input" et un "Table Output" que l'on relie entre eux.
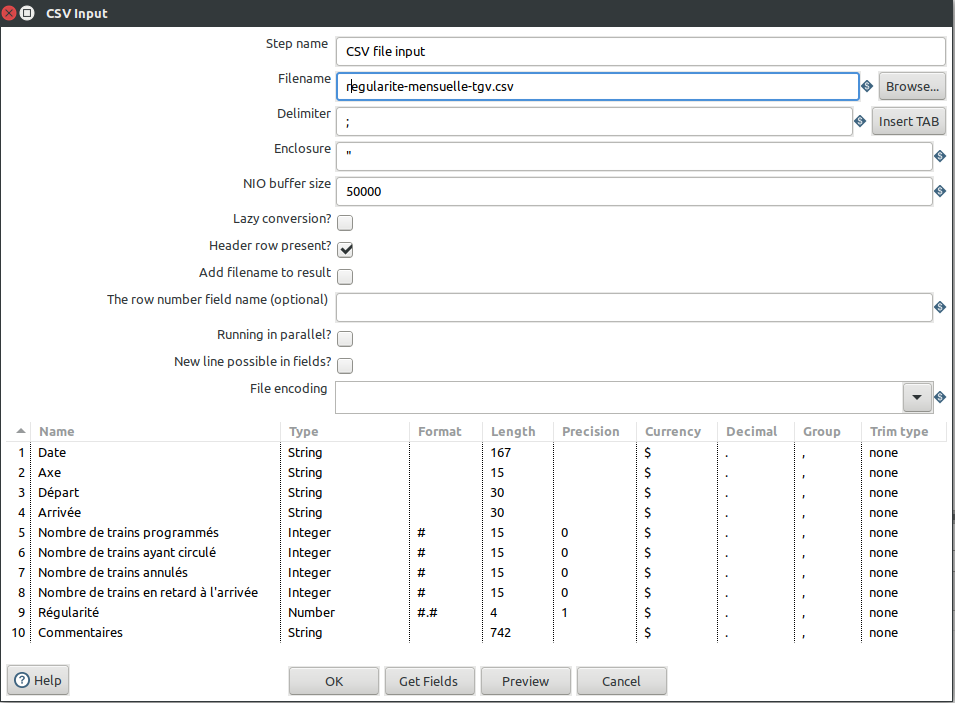
Passons ensuite au paramétrage de chacun des composants. Pour le CSV input, après avoir donné le chemin vers le fichier, vous pouvez lui faire deviner les entêtes et surtout les types de données et leur largeur par le bouton "GetFields" et en donnant un nombre de lignes assez grand (voir la totalité de votre fichier).
Pour la base de donnée, double clickez sur le composant "Table Output" et de là vous pouvez directement ajouter la connexion à la base, puis entrez le nom de table. Ensuite il faut créer soi même la base de donnée mais Pentaho nous donne le script et peut l’exécuter lui même.
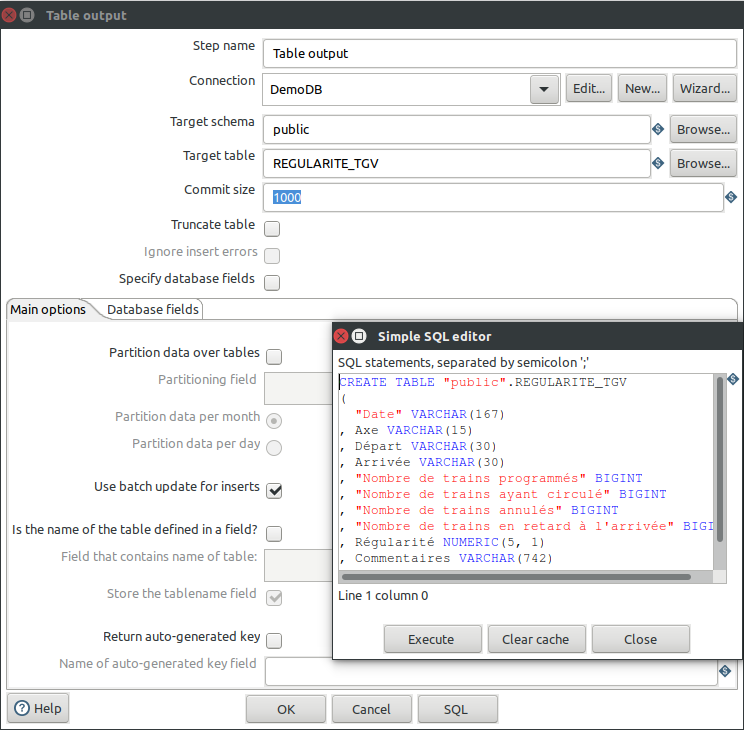
Comme pour Talend, il faut penser à changer le type de la colonne "Commentaires" en TEXT. Dommage qu'ils ne le fassent pas.
Executez ensuite la transformation et vous devriez avoir les lignes de chargées dans la base.
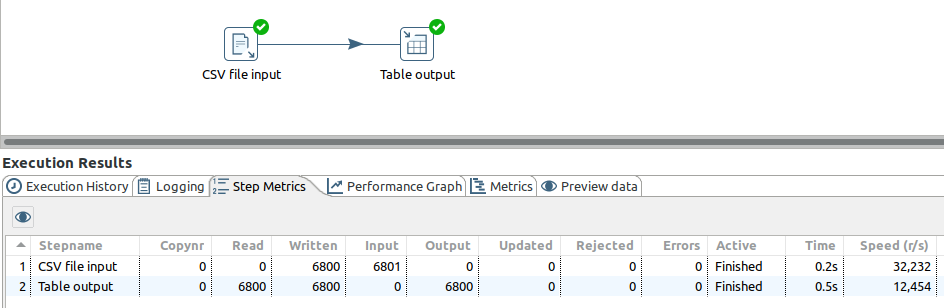
Il ne faut pas comparer ici les temps d’exécutions car TOS tournait dans une machine virtuelle alors que PDI était directement lancé sur l’hôte.
Ensuite
Une fois que les jobs/transformations sont paramétrées, vous serez ammenés à les améliorer, modifier... Il est bon du coup de gérer les versions:
-
pour TOS, les fichiers sont dans un workspace que vous pouvez suivre par un outil de versioning (Git pour ne pas le nommer).
-
pour PDI, le repository est en base de donnée et du coup il stock à chaque modification la date et l'auteur. Cela reste néanmoins moins puissant que Git.
Puis il faut pouvoir exécuter les jobs/transformations, sur votre poste ou sur un serveur, ou bien les intégrer dans un scheduler...
-
pour TOS, vous lancez un build du job qui génère du coup un script qui peut être exécuté sous Linux et Windows ou ajouté en crontab, ou bien un war qui peut être intégré dans un serveur d'application.
-
pour PDI, cela est un peu plus compliqué. Vous pouvez exécuter localement par batch (Kitchen pour les jobs et pan pour les transformations) ou sur un serveur distant avec Carte mais vous devez installer PDI sur le serveur ou bien en utilisant le BI Server et le plugin sparkl. Mais dans tous les cas, cela peut devenir vite lourd en maintenance.
Pour le suivi des exécutions, vous pouvez
-
sous TOS, ajouter des log ou stats catcher que vous redirigez vers une base de donnée ou un logstash par exemple. Par contre vous devez les ajouter dans chaque Job.
-
sous PDI, paramétrer dans les propriétes de la transformation
Conclusion
- Au premier abord et sur le papier les 2 outils sont très proche, y compris dans leur interface graphique. Au cours de leur installation et utilisation, nous remarquons tout de même 2 philosophies divergentes.
TOS
est plus orienté développement: il donne accès au code Java généré et le paramétrage est pensé comme un développement avec des Classes/Méthodes réutilisables (entre autres choses).
Il sera peut être plus brut à la prise en main mais certainement plus adapté à un usage structuré.
A noter qu'il existe un plus petit outil, Talend Data Preparation qui est plus orienté manipulation de fichiers de données par les utilisateurs finaux (un peu à la mode du self-BI).
PDI
semble plus simple d'utilisation au premier abord et nécessite moins de connaissances informatiques pour son utilisation et n'en reste pas moins très puissant. Comme vous avez pu le voir sur ce petit exemple, PDI a nécessité moins de paramétrages.
- Au niveau de la palette, cela dépend beaucoup de l'usage et donc on peut trouver plus facilement son bonheur chez l'un et pas chez l'autre mais les usages standards sont présents chez les deux. En terme de performances, il y a également trop de facteurs en jeux pour en avoir un meilleur que l'autre.